ETL-8G
Format
- fixed record length without control words
- 8 bits per byte, 8199 bytes per record
- big endian
- file formats and sample script
Files
- Each file contains 5 data sets except ETL8G_33 ([#records] = [#categories] * [#datasets], [#bytes] = [#records] * 8199).
- Each data set contains 956 characters written by a writer.
- Each writer wrote 10 sheets per data set ([#sheets] = 10 * [#data sets]).
| filename | #bytes | #records | #categories | #data sets | data set indices | #sheets |
| ETL8G_01 | 39191220 | 4780 | 956 | 5 | 1-5 | 50 |
| ETL8G_02 | 39191220 | 4780 | 956 | 5 | 6-10 | 50 |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| ETL8G_32 | 39191220 | 4780 | 956 | 5 | 156-160 | 50 |
| ETL8G_33 | 7838244 | 956 | 956 | 1 | uncertain | 10 |
Samples
| filename | record | metadata and JIS code in hex | image (0: white, 15:black) |
| ETL8G_01 | 1 | (1, 9250, ‘A.HIRA ‘, 1, 0, 0, 1, 24, 3552, 0, 8001, 16880, 0, 0) 0x2422 |  |
The images of the first 956 records:
ETL-8B2
ETL-8B2 contains binalized images from ETL-8G. The threshold is determined by T=λ∙h + (1-λ)∙μ, where h is Otsu’s threshold [j] and μ is the average of all intensity levels in ETL-8G [k]. For ETL-8B2, λ=0.25 [c].
Format
- Fixed Record Length without Control Words
- 8 bits per byte, 512 bytes per record
- Big endian
- File formats and sample scripts
Files
- Ordered by character major. Each data set contains 956 characters written by a writer.
- For each character, there are 160 writers ([#records] = [#categories] * 160).
- The first record of each file is zero padded dummy ([#bytes] =( [#records] * 512 for ETL8B2_1 and ETL8B2_2).
- The last 956 records are the model images presented to writers.
| filename | #bytes | #records | #categories | JIS X 0208 | note |
| ETL8B2C1 | 26214912 | 1+51200 | 320 | 2122-384D | The first record is zero padded dummy. |
| ETL8B2C2 | 26214912 | 1+51200 | 320 | 384E-4250 | |
| ETL8B2C3 | 26376704 | 1+50560 | 316 | 4253-4F43 | |
| 956 | 956 | 2122-4F43 | Last 956 records are model images |
Samples
| filename | record | metadata and JIS code in hex | image (0: white, 1: black) |
| ETL8B2C1 | 1 | (1, 9250, ‘A.HI’) 0x2422 | 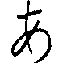 |
The images of the first 160 records: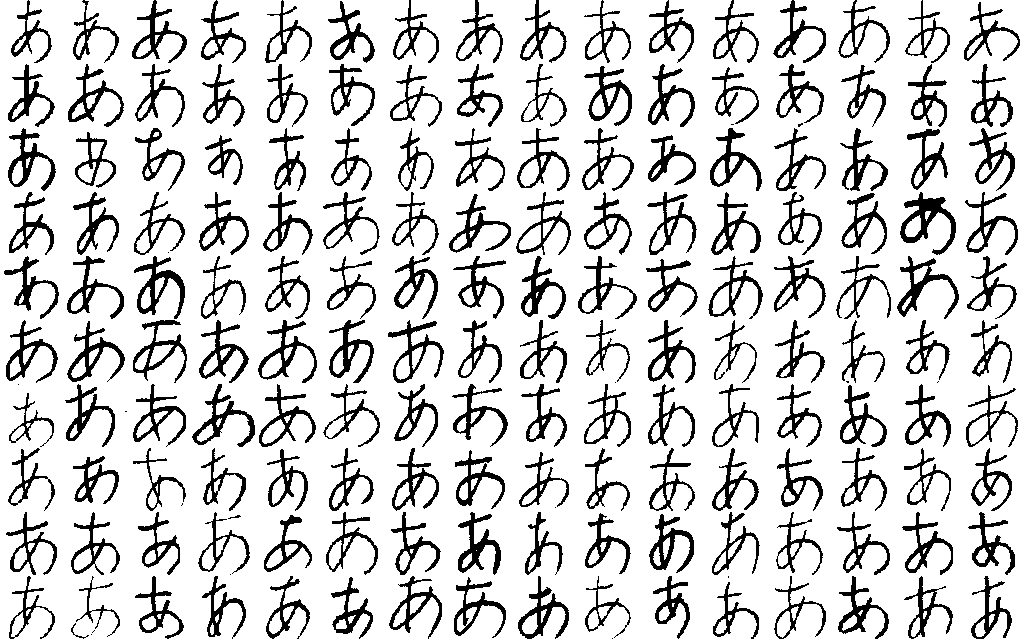
References
In Japanese only.
- 森俊二、山本和彦、山田博三、斉藤泰一: “手書教育漢字のデータベースについて”, 「電総研彙報」, Vol.43, Nos.11&12, pp.752–773 (1979-11&12).
- 斉藤泰一、山田博三、森俊二: “手書文字データベースの解析(IV) -教育漢字の統計量-”, 「電総研彙報」, Vol.44, No.4, pp.219–251 (1980-04).
- 斉藤泰一、山田博三、山本和彦、森俊二: “手書文字データベースの解析(V) -教育漢字データベースのパターン・マッチング法による評価-”, 「電総研彙報」, Vol.45, Nos.1&2, pp.49–77 (1981-01&02).
- 斉藤泰一、山田博三、山本和彦、森俊二: “手書漢字データベースについて -教育漢字-”, 「昭和56年度電子通信学会総合全国大会(昭56信学総全大)」, 1385, p.5-363 (1981-04.03).
- 斉藤泰一、山田博三、山本和彦、岡隆一、安田道夫、坂倉栂子、曾根裕文: “手書教育漢字データベースの目視による調査”, 「昭和57年度電子通信学会総合全国大会(昭57信学総全大)」, 1342, p.5-327 (1982-03.28).
- 斉藤泰一、山田博三、山本和彦: “手書漢字の方向パターン・マッチング法による解析”, 「電子通信学会論文誌(信学論)(D)」, Vol.J65-D, No.5, pp.550–557 (1982-05).
- 斉藤泰一、山田博三、山本和彦: “手書文字データベースの解析(VI) -方向パターン・マッチング法による教育漢字の解析-”, 「電総研彙報」, Vol.46, No.12, pp.695–725 (1982-12).
- 斉藤泰一、山田博三、山本和彦: “JIS第1水準手書漢字データベースETL9とその解析”, 「信学論(D) 画像処理特集号」, Vol.J68-D, No.4, pp.757–764 (1985-04).
- 斉藤泰一、山田博三、山本和彦: “手書文字データベースの解析(VIII) -方向パターン・マッチング法によるJIS第1水準手書漢字データベースETL9の評価-”, 「電総研彙報」, Vol.49, No.7, pp.487–525 (1985-07).
- 大津展之: “判別および最小2乗規準に基づく自動しきい値選定法”, 「信学論(D)」, Vol.63-D, No.4, pp.349–356 (1980-04).
- 斉藤泰一、山田博三: “判別しきい値選定法の一改良”, 「情報処理学会論文誌(情処学論)」, Vol.22, No.6, pp.596–599 (1981-11).