★ETL8作成経緯
ETL8は、 日本電子工業振興協会OCR用手書文字専門委員会において、 昭和55年(1980年)に、 OCRユーザ・メーカ・名古屋大学・その他、 1600人の方々から収集したOCRシートを、 電子技術総合研究所において、 TOSBAC-40C観測システムにより観測したデータベースで、 教育漢字881字種、平仮名75字種が納められています。
★観測仕様
- OCRシート仕様
- OCRデータ収集用紙
 : A4判, 83kg OCR用紙(特種製紙)(10種)
: A4判, 83kg OCR用紙(特種製紙)(10種) - ドロップアウト・カラー : No.114レディッシュオレンジ 50%スクリーン(大日本印刷)
- 文字枠 : 横 10mm、縦 10mm 文字枠ピッチ : 横 12.7mm、縦 15.24mm
- 文字枠数 : 13 x 16 = 208
- OCRデータ収集用紙
- 対象文字 (計 956文字)
- 教育漢字 : 881 (昭和23年内閣告示第1号「当用漢字別表」による)
- ひらがな : 75
- OCRシート収集
- 記入上の制限 : 「手書き漢字OCR用紙記入のお願い」
 で指定
で指定 - 筆記者数 : 延べ 1,600人(原則として一人10シート書いていますが複数人で10シートを書いたケースがあるため延べ表記になっています)
- 全サンプル数 : 152,960
- データ収集 : 日本電子工業振興協会 OCR手書文字専門委員会、名古屋大学
- 記入上の制限 : 「手書き漢字OCR用紙記入のお願い」
- 観測装置
- 入力装置 : 128×1点フォトダイオード・アレイセンサ (ADC 6bit)(半導体アレイ レチコン社製 RL-128EC)
- 標本化間隔 : 0.108mm x 0.1016mm
- 濃度レベル : 16 (4bit ← 6bit)
- 標本点数 : 128 x 127 = 16,256 pixels
- データベース作成
- 観測場所 : 電子技術総合研究所
- 使用計算機 : TOSBAC-40C(プログラム:)
- 作成年月 : 1980年2月
- 観測期間 : 1980年2月~??月
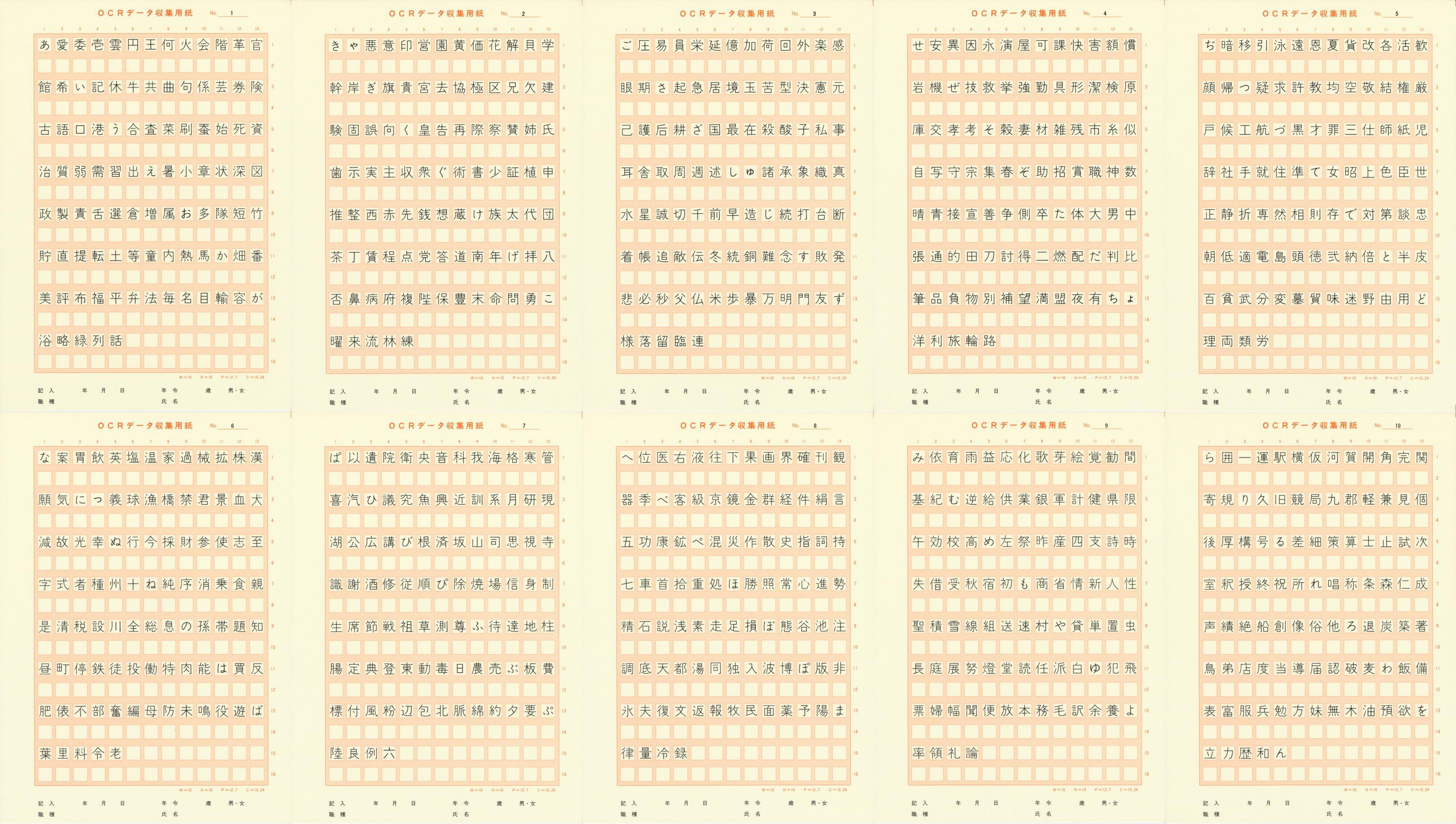

★ETL8データベース仕様
多値イメージ・ファイルのフォーマット
File Format
- G-Type Data Format
- Fixed Record Length without Control Words
- Logical record (8199 bytes) (1byte = 8bits)
- Sample script
Contents of Files
| File Name | Number of Records | No. of Categories | Number of Data Sets | Data Set Number | Number of Sheets |
| ETL8G-01 | 4780 | 956 | 5 | 1 – 5 | 50 |
| ETL8G-02 | 4780 | 956 | 5 | 6 – 10 | 50 |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| ETL8G-32 | 4780 | 956 | 5 | 156 – 160 | 50 |
| ETL8G-33 | 956 | 956 | 1 | uncertain | 10 |
2値イメージ・ファイルのフォーマット
File Format
- B-Type Data Format
- Fixed Record Length without Control Words
- Logical record (512 bytes) (1byte = 8bits)
- | Dummy | Sample 1 | Sample 2 | …. | Sample N | (No. of records = N+1)
- Sample script
Contents of Files
| File Name | Number of Records | No. of Categories | JIS Code (JIS X 0208) | |
| ETL8B2-1 | 1+ 51200 | 320 | 2122 – 384D | ‘1+’ means 1st record is dummy |
| ETL8B2-2 | 1+ 51200 | 320 | 384E – 4250 | |
| ETL8B2-3 | 1+ 50560 | 316 | 4253 – 4F43 | |
| + 956 | + 956 | 2122 – 4F43 | Last 956 samples = Model Images |
2値イメージの2値化しきい値Tは、 h(判別しきい値[j])とμ(多値イメージの全濃度平均値)とのλ分割点 T=λ・h+(1-λ)・μ を採用しました。[k] ETL8B2では、λ=0.25としました。[c]
収集サンプル
「田」全160サンプル 
★参考文献
- 森俊二、山本和彦、山田博三、斉藤泰一: “手書教育漢字のデータベースについて”, 「電総研彙報」, Vol.43, Nos.11&12, pp.752–773 (1979-11&12).
- 斉藤泰一、山田博三、森俊二: “手書文字データベースの解析(IV) -教育漢字の統計量-”, 「電総研彙報」, Vol.44, No.4, pp.219–251 (1980-04).
- 斉藤泰一、山田博三、山本和彦、森俊二: “手書文字データベースの解析(V) -教育漢字データベースのパターン・マッチング法による評価-”, 「電総研彙報」, Vol.45, Nos.1&2, pp.49–77 (1981-01&02).
- 斉藤泰一、山田博三、山本和彦、森俊二: “手書漢字データベースについて -教育漢字-”, 「昭和56年度電子通信学会総合全国大会(昭56信学総全大)」, 1385, p.5-363 (1981-04.03).
- 斉藤泰一、山田博三、山本和彦、岡隆一、安田道夫、坂倉栂子、曾根裕文: “手書教育漢字データベースの目視による調査”, 「昭和57年度電子通信学会総合全国大会(昭57信学総全大)」, 1342, p.5-327 (1982-03.28).
- 斉藤泰一、山田博三、山本和彦: “手書漢字の方向パターン・マッチング法による解析”, 「電子通信学会論文誌(信学論)(D)」, Vol.J65-D, No.5, pp.550–557 (1982-05).
- 斉藤泰一、山田博三、山本和彦: “手書文字データベースの解析(VI) -方向パターン・マッチング法による教育漢字の解析-”, 「電総研彙報」, Vol.46, No.12, pp.695–725 (1982-12).
- 斉藤泰一、山田博三、山本和彦: “JIS第1水準手書漢字データベースETL9とその解析”, 「信学論(D) 画像処理特集号」, Vol.J68-D, No.4, pp.757–764 (1985-04).
- 斉藤泰一、山田博三、山本和彦: “手書文字データベースの解析(VIII) -方向パターン・マッチング法によるJIS第1水準手書漢字データベースETL9の評価-”, 「電総研彙報」, Vol.49, No.7, pp.487–525 (1985-07).
- 大津展之: “判別および最小2乗規準に基づく自動しきい値選定法”, 「信学論(D)」, Vol.63-D, No.4, pp.349–356 (1980-04).
- 斉藤泰一、山田博三: “判別しきい値選定法の一改良”, 「情報処理学会論文誌(情処学論)」, Vol.22, No.6, pp.596–599 (1981-11).