ETL2作成経緯
ETL2は、 ETL1と同じ時期に同大型プロジェクトの一環として、 電子技術総合研究所と当時の東京芝浦電気株式会社との共同で作成されたもので、 大日本印刷株式会社および毎日新聞社の協力を得て、 特許広報および新聞に用いられる明朝体とゴシック体の活字文字データ 約5万字が納められています。 東京芝浦電気株式会社(現・東芝)で観測、編集が行われ、 観測は、TOSPICSで、編集は、TOSBAC-5600により行われました。
観測仕様
OCRシート仕様
OCRシート : B4判, 90kg 連用OCR用紙
文字サイズ : 新聞活字 8ポイント(活版印刷)、
特許広報活字 9ポイント(オフセット印刷)
対象文字 (計 2,184文字) (CO-59 Code)
ひらがな、カタカナ、英数字、記号、漢字
OCRシート収集
データ収集 : 大日本印刷(株)、毎日新聞社
全サンプル数 : 52,796
観測装置
入力装置 : ITVカメラ・スキャナ 240x240
標本化間隔 : 54μm x 54μm
スポット径 : 54μm
濃度レベル : 64 (6bit)
標本点数 : 60 x 60 = 3,600 pixels
データベース作成
観測場所 : 東芝総合研究所
使用計算機 : TOSBAC-40C TOSPICS システム(プログラム:)
作成年月 : 1973年10月
観測期間 : 1973年10月
{kind=link}
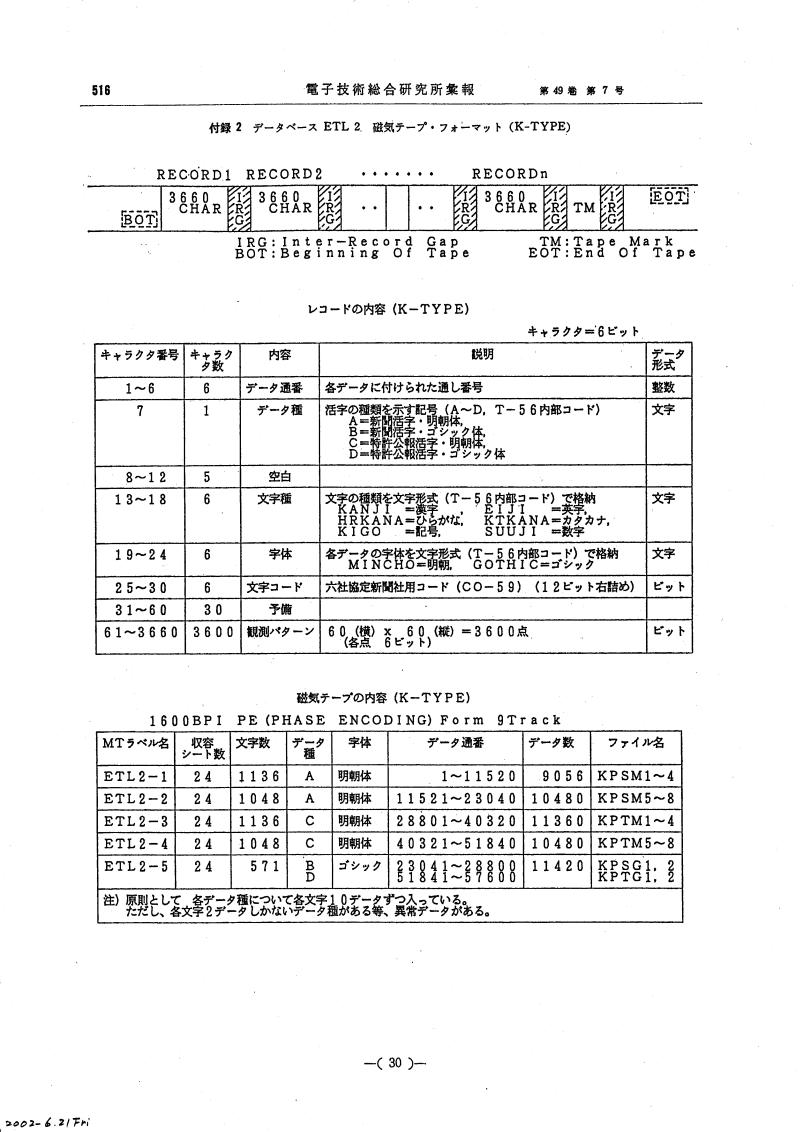
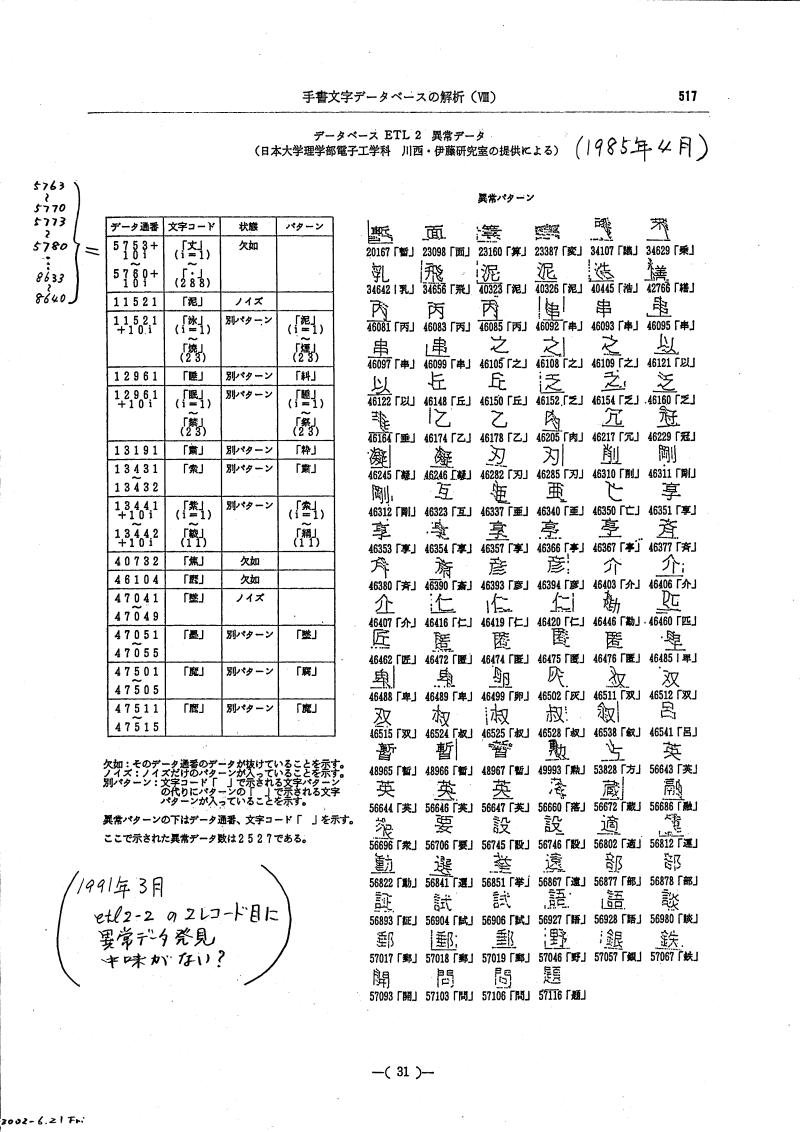
★ETL2データベースの内容
- Image file format / イメージ・ファイル・フォーマット
- Format and Contents / フォーマットと内容
- Illegal data 1 / 異常データ1
- Illegal data 2 / 異常データ2
- File Formats and Sample Script
{kind=link}
{kind=link}
{kind=link}
★参考文献
- 山田博三、森俊二: “手書文字データベースの解析(I)”, 「電総研彙報」, Vol.39, No.8, pp.580–599 (1975-08).
- 電総研、東芝: “漢字パターン・データ・バンク外部仕様書” (1973-10).
- 斉藤泰一、山田博三、森俊二: “手書文字データベースの解析(III)”, 「電総研彙報」, Vol.42, No.5, pp.385–434 (1978-05).
- 斉藤泰一、山田博三、山本和彦: “手書文字データベースの解析(VIII) -方向パターン・マッチング法によるJIS第1水準手書漢字データベースETL9の評価-”, 「電総研彙報」, Vol.49, No.7, pp.487–525 (1985-07).